Character video generation is a significant real-world application focused on producing high-quality videos featuring specific characters. Recent advancements have introduced various control signals to animate static characters, successfully enhancing control over the generation process. However, these methods often lack flexibility, limiting their applicability and making it challenging for users to synthesize a source character into a desired target scene. To address this issue, we propose a novel framework, AnyCharV, that flexibly generates character videos using arbitrary source characters and target scenes, guided by pose information. Our approach involves a two-stage training process. In the first stage, we develop a base model capable of integrating the source character with the target scene using pose guidance. The second stage further bootstraps controllable generation through a self-boosting mechanism, where we use the generated video in the first stage and replace the fine mask with the coarse one, enabling training outcomes with better preservation of character details. Experimental results demonstrate the effectiveness and robustness of our proposed method.
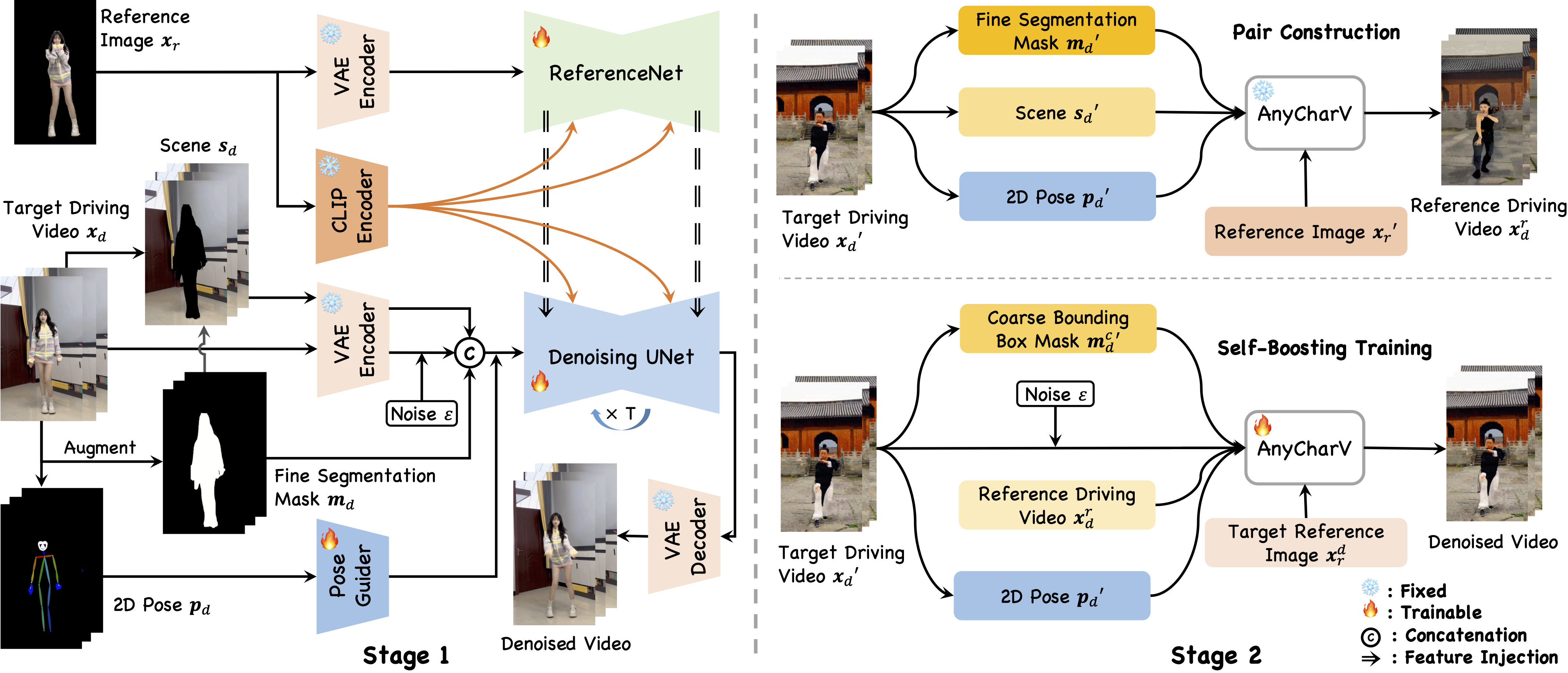
The overview of our proposed AnyCharV. We design a two-stage training strategy with fine-to-coarse guidance for controllable character video generation. In the first stage, we utilize a self-supervised manner to train a base model for integrating a reference character with the target scene, guided by fine segmentation mask and 2D pose sequence. In the second stage, we propose a self-boosting training strategy by interacting between the reference and target character using coarse bounding box mask guidance. Such a mechanism can better preserve the identity of the reference character and eliminate the bad influence caused by the mask shape. The CLIP encoder and VAE are always frozen. We train denoising UNet, ReferenceNet, and pose guider during the first stage, while only finetuning denoising UNet in the second stage.
Reference Character
Target Video
Generated Video

The reference character is generated by FLUX with prompt "A man on the beach" and the target video is generated by HunyuanVideo with prompt "A man doing warm-up exercises by the swimming pool, high definition".

The reference character is generated by FLUX with prompt "A man in the universe" and the target video is generated by HunyuanVideo with prompt "A man in sportswear running in a city park, high definition".
Qualitative results of combining AnyCharV with FLUX[4] and HunyuanVideo[5].
Reference Character
Target Video
Generated Video






Visualization results of the generated videos using our proposed AnyCharV model in multiple visual scenarios.
[1] Zhao, Yuyang, Enze Xie, Lanqing Hong, Zhenguo Li, and Gim Hee Lee. Make-a-protagonist: Generic video editing with an ensemble of experts. arXiv, 2023.
[2] Viggle. Viggle AI mix application. https://viggleai.io, 2024.
[3] Men, Yifang, Yuan Yao, Miaomiao Cui, and Liefeng Bo. "Mimo: Controllable character video synthesis with spatial decomposed modeling." arXiv, 2024.
[4] Black Forest, L. Flux. https://github.com/black-forest-labs/flux, 2023.
[5] Kong, Weijie, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong et al. "Hunyuanvideo: A systematic framework for large video generative models." arXiv, 2024.
@article{wang2025anycharv,
title={AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance},
author={Wang, Zhao and Wen, Hao and Zhu, Lingting and Shang, Chengming and Yang, Yujiu and Dou, Qi},
journal={arXiv preprint arXiv:2502.08189},
year={2025}
}
 AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance
AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance
